

Open-world evaluations for measuring frontier AI capabilities
Introducing CRUX, a new project for evaluating AI on long, messy tasks


This post is 8,000 words long—it is our new collaborative paper on an emerging type of AI evaluation. The paper is also published in a PDF format here.
Summary: AI models have started to saturate most major benchmarks. But does that mean they can build and ship a real product, or conduct a scientific experiment end-to-end, or navigate a government bureaucracy? Researchers have started testing AI in such real-world settings. We call these evals “open-world evaluations”. This essay defines open-world evaluations, surveys the lessons learned so far, and lays out best practices for conducting them.
We also introduce CRUX, a collaboration of 17 researchers from academia, government, civil society, and industry that will regularly evaluate frontier AI capabilities through open-world evaluations. In our first experiment, an AI agent built and published an iOS app to the App Store, making just two errors, one of which required manual intervention. This gives us an early indication of potentially useful capabilities and, more importantly, an early warning about the potential for AI-driven app store spam (we disclosed this result to Apple a month before publication).
We hope to conduct similar experiments to surface early warnings across other real-world domains; this will be one of our main empirical projects over the coming year.
The authors are: Sayash Kapoor, Peter Kirgis, Andrew Schwartz, Stephan Rabanser, J.J. Allaire, Rishi Bommasani, Magda Dubois, Gillian Hadfield, Andy Hall, Sara Hooker, Seth Lazar, Steve Newman, Dimitris Papailiopoulos, Shoshannah Tekofsky, Helen Toner, Cozmin Ududec, Arvind Narayanan
How should we track and predict AI capabilities? The AI community’s dominant answer today is benchmarking. For example, METR’s time horizon graph has been used by policy analysts, industry leaders, and organizations researching AI risks to argue that AI capabilities are rapidly increasing.
But benchmarks can both overestimate and underestimate progress. To turn a task into a benchmark, it needs to be precisely specified and automatically verifiable. The catch is that whatever is precise enough to benchmark is also precise enough to optimize for, allowing AI agents to excel at such tasks. On the flip side, low accuracy on benchmarks might result from incidental failures such as encountering CAPTCHA on a website, even if agents are capable of solving the underlying task.
To address these limitations, many researchers are turning to a new kind of evaluation: long, messy, real-world evaluations that go beyond benchmarks. Nicholas Carlini at Anthropic used Claude agents to build a C compiler that could compile the Linux kernel. Anthropic and Andon Labs designed a free-form experiment where Claude was tasked with maintaining a small shop in their office. While benchmarks consist of dozens of tasks evaluated in an automated way, open-world evaluations consist of small samples, often require human intervention, and are evaluated in an open-ended way, such as by analyzing agent logs.
It is easy to dismiss these as unscientific: each such evaluation has a sample size of 1, and they lack standardization and reproducibility. Despite these limitations, we think such evaluations are important for collecting evidence about AI capabilities. They can provide early warnings about emerging capabilities to inform efforts at building societal resilience, help evaluators identify blind spots in existing benchmarks, and give companies a clearer picture of what tasks AI systems could soon carry out, informing strategic decisions about AI. We call them open-world evaluations.
In this essay, we conceptualize open-world evaluations, review past examples to identify best practices and pitfalls in conducting them, and introduce CRUX, a project aimed at regularly conducting new open-world evaluations. Here are our main insights:
Open-world evaluations are an important emerging class of AI evaluation. As AI systems become more capable, evaluations to elicit frontier capabilities must also increase in complexity. Open-world evaluations are the latest in a long line of evaluations of increasing complexity. We survey 10 prominent open-world evals conducted over the last year to identify best practices and key takeaways.
CRUX (Collaborative Research for Updating AI eXpectations) is our attempt at systematically conducting open-world evaluations. The team consists of collaborators from government, academia, and non-profits, many of whom have led open-world evaluations, and who have a range of expectations about the future of AI. We aim to provide empirical evidence about the present capabilities of AI systems, even if they are currently costly, and to provide early warnings for capabilities that might soon be widespread. We plan to release new open-world evaluations regularly.
In our first CRUX experiment, we tasked an AI agent with developing and publishing a simple iOS app to the App Store. Many benchmarks test agents’ ability to write code. But publishing an iOS app involves many other steps: signing the app, publishing a privacy policy on a webpage, filling out Apple’s forms, and taking the app through the review process. We were more interested in whether the agent succeeded at the real-world requirements of publishing the app rather than its ability to write code, so we tasked it with building a simple app and taking it through the iOS App Store submission process.
The agent was successful after making two errors, one of which required manual intervention (forgetting where the correct credentials were stored and fabricating a fictional phone number for the App Store review process). The process of developing and publishing the app cost about $1,000. The app is now live on the iOS App Store. We think the cost could have been far lower: the app development and submission only cost $25; the vast majority of tokens were spent monitoring the app’s status. We reached out to Apple a month before the publication of this essay to disclose the results of our experiment. App store operators should prepare for and police spam submissions, as they might soon see thousands of applications submitted autonomously using agents.
How can we improve open-world evaluations? What’s next? To increase the usefulness of open-world evaluations, evaluators should specify what and how much human intervention is allowed, release logs collected while the agent was solving the task, and analyze logs to report what an agent did in the course of solving the task. In future CRUXes, we will evaluate AI R&D automation, AI governance, and many other areas.
Open-world evaluations are an important emerging class of AI evaluation
In this section, we define open-world evaluations and survey the emerging landscape of such evaluations to extract insights about their success and limitations. We discuss areas where open-world evals can overcome some of the blind spots of benchmarks. In our view, as AI systems become more capable, evaluations to elicit frontier capabilities must become more complex; open-world evaluations are the latest in a series of evaluations of increasing complexity. We also discuss the limits of open-world evaluations compared to benchmarks.
We discuss five loose criteria that define open-world evaluations below (see “What are open-world evaluations?”). But it is worth noting that the line between long, complex benchmark tasks and open-world evaluations is blurry. Indeed, many of the evaluations we discuss are sandboxed. We still include them in our list of open-world evals, because they satisfy our other criteria (e.g., Carlini’s C compiler is sandboxed, but involves just one long-running task, human intervention, and qualitative analysis as part of the evaluation).
Benchmarks can both overestimate and underestimate progress
People with drastically different views on AI agree that current AI benchmarks might soon be saturated. Many prominent benchmarks have been saturated in the last two years, and evaluators have raced to release “successor” benchmarks. Many of these updated benchmarks are themselves near saturation.
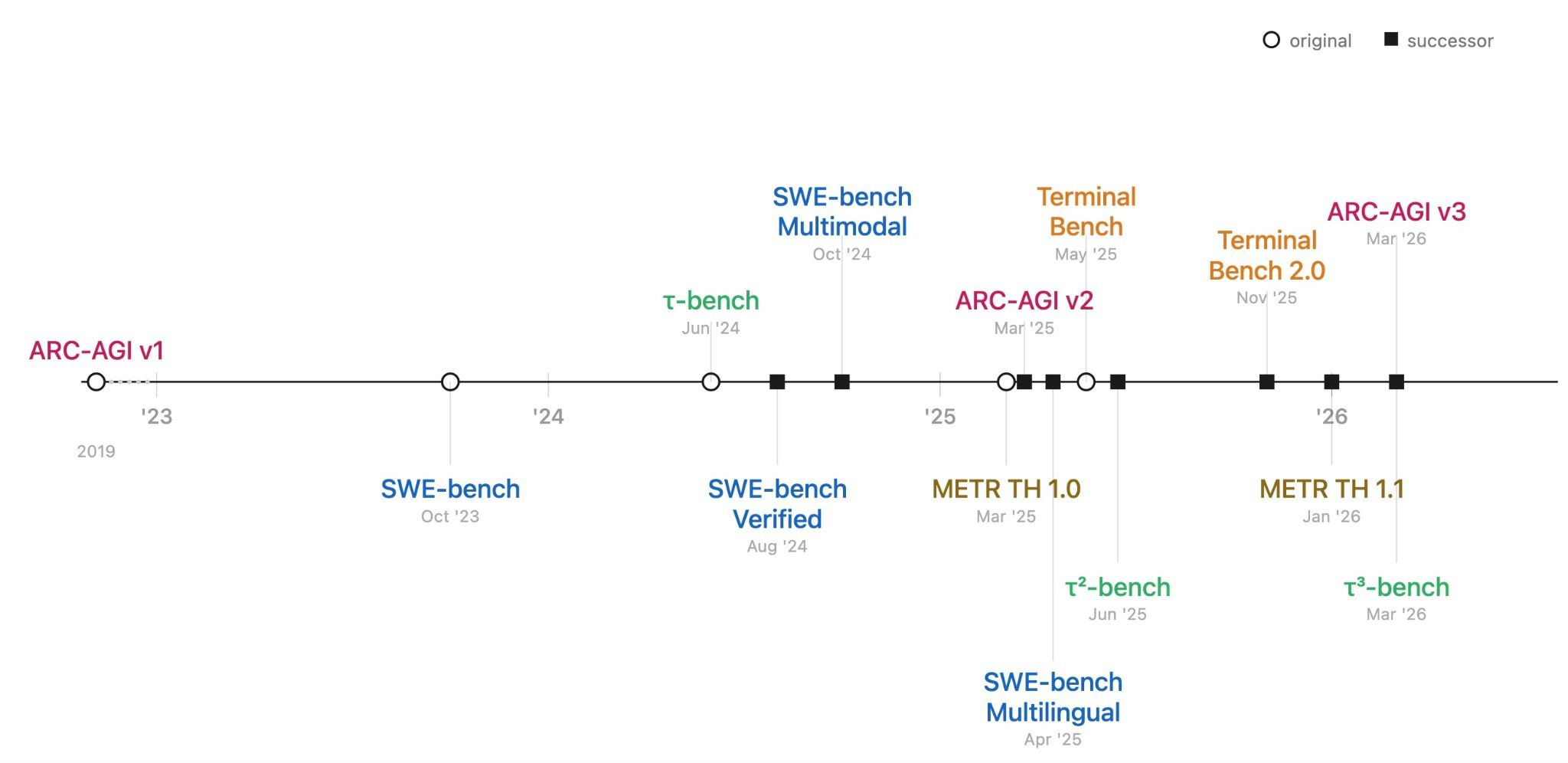
Does this mean AI systems will soon be capable of solving any task? Not necessarily. Benchmark improvements could indicate real capability gains, but they can also overstate progress: for example, because benchmarks have limited construct validity—they may test accuracy on narrow tasks rather than general ability—and they don’t test how well agents handle the messiness of real-world environments.
On the flip side, benchmarks could also underestimate progress due to challenges in the environment or infrastructure that are only incidental to the capabilities being measured, such as encountering CAPTCHA.
One way to get a fuller picture is to use metrics other than accuracy. For example, in a recent preprint several of us coauthored, we showed that even though agents are improving drastically in terms of capability metrics (such as average accuracy), they have improved much more slowly on metrics that measure reliability. Similarly, many agent solutions to SWE-bench tasks that were judged correct because they pass tests, would nevertheless be rejected by project maintainers.
But this still doesn’t allow us to measure the upper bounds of AI capabilities. Capabilities that are possible today (even if only under favorable conditions) might soon be widespread, and we need to anticipate them before they are. Providing such early warnings gives businesses extra time to capitalize on new opportunities, institutions to build resilience, and policymakers to address risks.
Now let’s discuss in more detail why benchmarks can both overestimate and underestimate capabilities. They can overestimate capabilities because:
Benchmarks resemble tasks amenable to modern reinforcement learning (RL) techniques. To turn a task into a benchmark, it needs to be precisely specified and automatically verifiable. But whatever is precise enough to benchmark is also precise enough to optimize for, and modern RL training runs increasingly resemble the shape of the benchmarks themselves. This makes it easy to saturate any task that can be measured using benchmarks.
This is already the case for leading evaluation platforms like Harbor, which double as RL training platforms. As a result, AI models could be directly trained on data from many prominent benchmarks included on these platforms. Even if benchmarks include held-out test sets, models might be trained on tasks from the training set that look very similar to those they would encounter in the test set. So benchmarks don’t help us understand how well performance generalizes to the real-world.
Benchmarks avoid real-world messiness. Real-world tasks involve underspecified interactions that can’t be fully sandboxed, such as responding to unexpected situations or navigating environments that are open-ended. Benchmarks can take some steps to simulate messy environments, but they can’t fully replicate them.
Benchmarks can also underestimate capabilities, because:
Eliciting frontier capabilities is costly. Running large-scale, long-running experiments is expensive, making it impractical to achieve the sample sizes that benchmarks rely on. Anthropic’s C compiler cost ~$20k; the task we describe running below (developing and publishing an iOS app for CRUX #1) cost ~$1,000. We can’t run such experiments hundreds of times, limiting the budget and complexity for each benchmark task.
Average performance is very different from upper-bound capability elicitation. Trying to run dozens (or 100s) of tasks in a benchmark suite is only necessary to measure average performance. But when we are trying to understand the frontier of what agents can do, the goal shifts to understanding best-case performance: what can agents accomplish when given sufficient resources and support to work around incidental failures? This is necessary for providing early warnings for capabilities that might soon be widespread.
Human intervention can help elicit capability upper bounds. Agents working on real-world tasks could encounter policy refusals, require solving CAPTCHAs, or encounter other infrastructure issues where they get stuck. This could negatively affect their performance. But these failures are only incidental to the capability being measured. If human operators can handle these, it would allow us to elicit upper bounds of capability. Such manual intervention is impractical for 100s of benchmark tasks each time they are run.
As AI capabilities improve, sandboxed evaluations that test AI capabilities in coding, deep research, and customer service require intensely engineered environments to challenge agents and avoid contamination or reward hacking. For example, the performance of agents on web benchmarks has been affected by how often agents encounter CAPTCHA, rather than eliciting the true underlying capabilities of agents. Recent work has highlighted AI agents finding answers online, exploiting bugs in evaluations, and producing code that passes tests but fails to meet standards for production. This highlights the need for a shift towards deeper qualitative evaluations of AI agent performance that can help us better understand failure modes and problem-solving strategies that can be lost in the barrage of average benchmark scores.
But these threats to validity are not straightforward to address. We can conduct qualitative log analysis for benchmarks to address some of these concerns, but even when we find validity issues in benchmark results using log analysis, there’s little we can do about it except releasing an updated benchmark, which could take a few months. Open-world evals allow us to conduct dry runs to fix issues before the real test run, and manually intervene to fix issues found during the evaluation.1
Of course, benchmarks can be helpful despite these limitations.2 And open-world evaluations have their own limitations, which we discuss later in this paper. That said, we hope this list illustrates the systematic blind spots in benchmarking. As AI agents become more capable, the gaps we identify between traditional benchmarking and real-world capability will continue to grow. Success metrics will need to be multi-faceted to capture the diversity of objectives in a given task. Benchmarks will need to incorporate key bottlenecks (human assistance) and messy environments (internet navigation), each of which introduces additional issues of internal and external validity. Open-world evaluations offer an alternative.
What are open-world evaluations?
As evaluation methods have matured alongside AI capabilities, a gradient in evaluation has emerged. At one end are simple, automated, scalable methods that work well for early-stage capabilities. At the other end are richer, more labor-intensive methods that become necessary as capabilities improve and saturate simpler metrics.
As capabilities in a domain improve, evaluations further along the gradient become important to get insights that are complementary to simpler evaluations. We think of this gradient as having roughly five levels so far, each with their strengths and limitations:
Q&A benchmarks (e.g., MMLU, GPQA): useful for broad knowledge assessment, but increasingly saturated for frontier models. Often formatted as multiple-choice questions for ease of grading, but as a result have low construct validity, since users rarely interact with models by asking multiple-choice questions.
Open-ended chat benchmarks (e.g., WildBench, Arena-hard-auto): capture more nuance, but still limited to single-turn or short interactions.
Outcome-only agent benchmarks (e.g., SWE-Bench, WebArena): test agent performance on real tasks, but only measure whether the task was completed, not how. As a result, they have limitations. For example, most passing SWE-Bench solutions are not accepted by repository maintainers.
Agent benchmarks with log analysis (e.g., UK AISI transcript analysis, METR Time Horizon): go deeper by examining how agents succeed or fail and uncovering errors and reward hacking by analyzing agent logs. But they still operate in sandboxed environments with predefined tasks.
Open-world evaluations: long-horizon tasks in real-world environments, where success can’t be neatly specified or automatically graded. This allows eliciting upper bounds of capabilities. But this comes at the cost of lack of reproducibility and standardization (which are both benefits of benchmarking; see section on Limitations).
Some evaluations blur the categories of this spectrum. For example, OpenAI’s GDPVal, a long-horizon agent benchmark, is designed to be manually graded based on expert’s opinions on quality. This structure is very similar to an open-world evaluation, though they primarily focus on outputs but not on analyzing the logs. At the same time, results on GDPVal are commonly reported using GDPval-AA, which uses automated LLM grading; this evaluation setting resembles an outcome-only agent benchmark.
Open-world evaluations consist of running agents on a small number of long-horizon tasks in real-world settings, and qualitatively evaluating their results using tools for log analysis. These evaluations are complementary to benchmarking and help address many of their limitations. They can also uncover tasks that remain out of reach for current AI systems for future benchmarking efforts.
We provide a rough taxonomy to clarify the boundary of what constitutes open-world evaluations. No single dimension determines whether an experiment qualifies as “open-world”. Instead, it depends on the overall pattern across all of the dimensions below.
Openness. Is this evaluation in a real-world deployment setting (as opposed to a sandboxed environment)?
Complexity/length. Does the task require a human days or weeks at a time to complete (as opposed to a few minutes or hours)?
Number of tasks. Is this a stand-alone task or a small set of tasks (as opposed to a large evaluation suite or benchmark)?
Human intervention. To help elicit upper-bounds of capabilities, are humans able to intervene when agents hit a hurdle (as opposed to just setting up the environment or resolving setup issues)?
Method of evaluation. Does the evaluation primarily consist of in-depth log evaluation (as opposed to the result driven by a single average metric)?
When do we call something an evaluation as opposed to simply using agents to accomplish something novel? For example, Anthropic used AI agents to find security vulnerabilities in leading open-source software such as Mozilla Firefox—is this an example of an open-world evaluation? We still consider these open-world evals if the role of the agent is systematically and publicly documented (including the parts carried out by the agent carried and the human experts, and the end result).
The line between complex benchmark tasks and open-world evaluations is also blurry. For example, some evaluations in our list of open-world evals below are sandboxed (e.g., Claude Plays Pokemon and Anthropic’s C compiler were both run in sandboxed environments, but we still consider them open-world evaluations because they consist of a single, complex, long-running task, have human intervention during the evaluation, and are evaluated qualitatively).
The two types of evals are also complementary: we could imagine using open-world evaluations to understand what tasks remain unsolvable by agents as a first step towards building new benchmarks, and also use open-world evals to evaluate agents on messy real-world tasks that are not amenable to being benchmarked.
Finally, we don’t mean to imply that open-world evaluations are categorically more informative for understanding AI progress compared to benchmarks. Indeed, we discuss many limitations of open-world evaluations later in this section. Rather, as AI capabilities increase, open-world evaluations become important as an additional complementary signal of AI capabilities.
An incomplete survey of open-world evaluations
Over the past year, researchers at AI labs, universities, non-profits, and independent groups have begun running open-world evaluations. These share a common structure: give a capable AI agent a hard, real-world task with a long time horizon and observe and analyze its behavior in detail. Some notable examples:
Anthropic, Claude Plays Pokemon (Feb 2025). Anthropic launched a Twitch livestream in which Claude 3.7 Sonnet played Pokemon Red. While not a real-world deployment, the experiment was an early example of setting an AI agent up in a relatively open environment compared to typical benchmarks. While the project illustrated progress in AI computer use with minimal scaffolding, the demonstration also clearly illustrated the limitations of early 2025 agents––Sonnet 3.7 remained stuck in a level for nearly 80 hours.3
AI Digest, AI Village (April 2025-present). The AI Village gives multiple AI agents their own computer environments and a shared group chat, then tasks them with open-ended real-world goals like fundraising for charity, organizing real in-person events, making word games, and gaining subscribers on Substack. Across different experiments in 2025, the project highlighted persistent failure modes of hallucination, mis-calibration, and unproductive loops, but also documented notable improvements from late 2025 agents on these dimensions.
Anthropic/Andon Labs, Project Vend (June 2025-present). Anthropic partnered with Andon Labs to have a scaffold using Claude 3.7 Sonnet (nicknamed “Claudius”) operate a small automated store in their office. The agent managed inventory, set prices, and interacted with customers over several weeks, revealing a rich set of failure modes around manipulation, prioritization, and real-world decision-making. A second phase expanded the experiment to multiple locations, used newer models, and included a red-teaming exercise by the staff at the Wall Street Journal. The agent lost nearly all revenue from poor planning, hallucination, and excessive discounts. Anthropic’s follow-up was more successful, advertising positive profit each week, but the staff at the WSJ were still able to successfully jailbreak “Claudius,” leading it to give all products away for free. Andon Labs recently began a third phase to the project where they gave a Claude-based agent, “Luna,” a three year lease to a brick-and-mortar store in San Francisco and tasked it with making a profit as the “manager,” including hiring human employees, designing the brand, and making product selections.
Lin, Cursor browser experiment (Jan 2026). Wilson Lin at Cursor coordinated hundreds of GPT-5.2 agents to build a web browser from scratch, running uninterrupted for one week. The resulting browser (”FastRender”) consisted of over a million lines of Rust with a from-scratch rendering engine. It could render simple websites but was far from production-ready. The project was notable for its exploration of hierarchical multi-agent coordination at scale and the specific failure modes that emerge when agents work on a project for days rather than minutes.
Carlini, C compiler (Feb 2026). Nicholas Carlini at Anthropic tasked Claude with building a C compiler from scratch, spending roughly $20k in API costs. The agent produced a working compiler for compiling the Linux kernel and passed a large fraction of standard test suites, revealing detailed information about where agents excel (systematic code generation, test-driven iteration) and where they struggle (complex optimization passes, debugging subtle spec violations).
Ho, “How Close is AI to Taking my Job” (Feb 2026). Epoch researcher Anson Ho had Claude Code and ChatGPT Atlas attempt to autonomously complete three challenging work tasks at Epoch: replicating an interactive web interface for a 40 parameter economic model, writing an article in Epoch’s style on AI progress in 2025, and porting an article from Google Docs to Substack and Epoch’s website. The project highlighted the persistent bottlenecks of formatting and hallucinations in successful knowledge-work tasks.
Choi, GPT 5.3 Codex Builds a Design Tool (Feb 2026). OpenAI’s Derrick Choi had GPT-5.3 Codex run autonomously for 25 hours, generating 35,000 lines of code, to build a “design tool” from scratch. The post noted that the agent showed impressive planning, memory, and verification processes from the agent, though it did not provide substantive analysis of the capabilities and limitations of the finished product.
Faulkner, Next.js Reimplementation (Feb 2026). An engineer at Cloudflare used Claude with OpenCode to release vinext, a reimplementation of the popular frontend web framework Next.js on Vite rather than React. While the initial blogpost advertised coverage of 94% of Next.js for only $1,100 in API costs, follow-up analyses highlighted persistent security limitations and low generalizability to other domains of software given the importance of human-built testing and infrastructure of both Vite and Next.js.
Papailiopoulos, “Can You Train a Computer” (March 2026). Dimitris Papailiopoulos and collaborators tested whether Claude Code and OpenAI Codex could train a transformer to function as a general-purpose computer. The experiment included both a fully autonomous round, where both agents failed and reward-hacked solutions, and a human-guided version, where Claude Code succeeded and displayed meaningful generalization, including solving multi-step computations never seen in training.
Karpathy, Nanochat Autoresearch (March 2026). Using an existing open-source project, nanochat, for GPT-2 level LLM training, Andrej Karpathy built a simple automation pipeline for AI agents to optimize training in 5 minute increments. The agent has complete autonomy to adjust the architecture, hyperparameters, optimizers, and batch sizes. In a follow-up, Karpathy shared that autoresearch made progress against “Time to GPT-2” (measured with 8xH100 GPUs), dropping this metric by 11% in 2 days.
We plan to collect a running list of such evaluations (and the key takeaways and limitations for each of them) on cruxevals.com. The increase in AI capabilities has allowed people across domains to conduct such evaluations and figure out if AI systems can carry out tasks they are experts on, resulting in growing interest in such evaluations. In just the past week, there have been many significant open-world evaluation releases, including MirrorCode by Adamczewski et al., which tasked agents with reimplementing large programs, a set of automated alignment research case studies by Wen et al., and an exercise using Claude Code to train models to forecast the outcome of the recent Masters golf tournament by Huang.
Limitations of open-world evaluations
While open-world evaluations are helpful at addressing some blind spots in benchmarking, they also suffer from many limitations. There remains a genuine tradeoff between developing better benchmarks and investing in open-world evaluations. Benchmarks give evaluators control over the task and allows evaluations to occur in controlled environments, but are less useful for understanding agents’ performance on open-ended tasks. Open-world evaluations sacrifice sandboxing and evaluator control to improve the construct validity for the task and elicit upper-bound capabilities. Concretely, open-world evals have the following limitations:
Lack of reproducibility and standardization: Benchmarks have been successful because they provide coordinating functions for the AI community. Researchers can develop and test new methods independently, and validate if these methods work well on benchmarks to get the community’s attention. The culture of benchmarking runs so deep that David Donoho called it the “secret sauce“ for the success of the AI/ML community over the last 50 years. Open-world evaluations give up the reproducibility and standardization that made benchmarking so successful.
Hard to compare agents: Benchmarks offer a relative comparison between different models/agents. But since open-world evaluations are often run one or a handful of times, the run-to-run variability might be higher than the difference between different agents’ performance. As a result, open-world evaluations are not useful for comparing the accuracy of different models or agents.
The need for domain expertise: Evaluating whether an agent succeeded in an open-world evaluation can be challenging. Verification of the agent’s work might require deep domain expertise and time, especially if the task is open-ended.
Incomplete recall of log analysis: Even if automated log analysis is used to analyze open-world evaluations, it can never be considered complete. Agent transcripts from long-horizon tasks can run to hundreds of millions of tokens, making thorough human review impractical. And because agent behavior in these tasks is complex, there is no guarantee that a given round of analysis will surface all noteworthy behaviors or errors. This limitation does not apply in the same way to benchmarks, where success criteria are predefined and automatically verified. Releasing logs publicly so that a broader community can examine them is one way to partially mitigate this concern.
Blurry success criteria: Given the potential for human intervention, it is hard to cleanly delineate the agent’s performance from the help given to it by the human.
Non-stationary environments: In open-world evals, agents can interact with open-ended environments such as the internet.4 This makes it hard to make generalizable claims about the agent’s capabilities as opposed to information it can access via the internet (or another open-ended environment). For example, could an agent solve a hard software engineering task because it is genuinely competent at such tasks (and will therefore be able to solve novel software engineering tasks), or because it was able to look up a specific task online (and won’t be able to solve a novel task)? It is also challenging to compare agent performance over time. For example, the internet contains a growing list of implementations or hints that an unsandboxed agent can pull from.
How different stakeholders can use open-world evaluations
Open-world evaluations have limitations, but they can be helpful in addressing the blind spots of benchmarks. We think they can benefit a number of stakeholders:
Policymakers: The diffusion of AI across domains lags behind improvements in capabilities. This allows institutions to adapt as AI systems become more capable. Open-world evaluations can further increase this lead time by providing early warnings of what agents could soon be able to do autonomously and at scale, giving institutions time to build resilience. For example, Anthropic‘s recent work on discovering cybersecurity vulnerabilities using AI could spur efforts to rapidly adopt AI for defensive cybersecurity, especially in critical software infrastructure.
AI evaluators and researchers: Open-world evaluations offer a complementary signal to benchmarks by testing capabilities that are structurally resistant to benchmarking, such as solving messy real-world tasks. Analyzing agent logs allows us to uncover instances of the agent taking shortcuts and reward hacking. On the flip side, they can find areas where agents develop new insights or surpass previous limitations. For example, in our iOS app development evaluation, we identified that the agent modified its approach to be more token efficient, which allowed it to drastically reduce the cost of solving the task, without any input or instruction from our end.
Frontier AI developers: AI developers should actively support and participate in external open-world evaluation efforts by providing access (such as pre-release access to models) as well as safe harbors for third-parties conducting evaluations that might not adhere to developers’ terms of service (such as for evaluating safety). Open-world evaluations by independent third parties could surface findings that internal red teams miss if they optimize for known threat models.
New models are also saturating benchmarks. For example, Anthropic’s Mythos Preview system card notes that the model “saturates many of our most concrete, objectively-scored evaluations,” leaving them with noisier methods for assessing capabilities. Open-world evaluations could offer a complementary way to stress-test models in realistic settings that benchmarks can no longer distinguish.
To foster an ecosystem of open-world evaluations, it is important to develop shared best practices and build toward a cumulative body of evidence about what agents can and can’t do. That is what we are trying to do with a new project called CRUX.
Introducing CRUX: Collaborative Research for Updating AI eXpectations
CRUX is a project for operationalizing open-world evaluations. We aim to conduct open-world evaluations on a regular basis. Each evaluation will involve a long-horizon, real-world task; the implementation of an agent scaffold that could in theory allow agents to solve the task; and detailed analysis of what the agent did in order to solve a task. Our team consists of researchers spanning industry, academia, and non-profits. Many people on the team have conducted open-world evaluations.
In addition to conducting evaluations, we also want to develop mechanisms to provide early warnings for AI capabilities that will soon be widespread. For example, if AI agents can almost autonomously develop and publish apps (our task for the first iteration of CRUX; discussed in the next section), app store operators such as Apple and Google might soon need to update their policies to manage spam submissions.5
This requires eliciting upper-bounds of capabilities—often filling in missing incidental capabilities (such as filling out CAPTCHA) with human input. Open-world evaluations are a good fit for this particular style of evaluation, since they allow us to deeply understand AI systems’ capabilities.
Another advantage of open-world evaluations is that we don’t need to develop a large task suite or design complex environments or sandboxes before conducting evaluations, since each task only needs to be carried out and evaluated a small number of times. This allows us to conduct new evaluations regularly. We plan to design a new CRUX evaluation, analyze results, and publish our analysis on new tasks every 1-2 months.
Our first evaluation tests if AI agents can autonomously develop and publish apps to the iOS App Store; we discuss this in the next section. In future iterations, we plan to expand to a wide range of domains, including tasks on AI R&D automation, AI governance, complex software engineering, and real-world physical tasks.
CRUX #1: Can AI agents autonomously develop and publish an iOS app?
The question of whether AI agents can write software has been extensively studied, both through benchmarks like SWE-Bench and Terminal Bench, and through open-world evaluations like the C compiler and browser experiments discussed earlier in this essay. Agents have shown strong coding capabilities (though questions of code quality and reliability remain unresolved).
Meanwhile, a task that has not been evaluated as closely is whether agents can handle the non-coding aspects of software deployment, such as satisfying platform requirements and interacting with review systems they do not control. For our evaluation, we tasked an agent with building a mobile app from scratch and publishing it on the iOS App Store.
We prompted the agent to develop and publish a simple app to the App Store. We weren’t primarily interested in the agent’s software engineering ability, but rather its ability to interact with Apple’s App Store submission process. This process requires developers to configure signing certificates and provisioning profiles, prepare screenshots and metadata, draft and host a privacy policy at a public URL, fill out compliance questionnaires, and submit the app for review by Apple’s team. Reviewers may reject the app for technical or policy reasons, requiring the developer to diagnose the issue, make changes, and resubmit. This process typically takes several days and involves interacting with systems and reviewers that the developer does not control.
The agent was responsible for every step of the process except those where human involvement is required by policy, such as setting up the Apple Developer account and hitting publish to release the app to the App Store. Specifically, the agent handled writing the code, building the app, preparing metadata, drafting and hosting a privacy policy, submitting it for review, and handling any feedback. (We provided the agent access to a Mac VM, a GitHub account, an Apple developer account, and a Gmail account.)
The success criterion was whether the agent got the app published on the App Store. We logged how many manual interventions the agent needed us to make to solve the task. The agent had the option to ping the team for support; we monitored the agent’s progress once a day. The lower this number, the better the agent performs.
In addition, if agents can do this autonomously (or are close to being able to do so), this serves as an early warning for Apple’s review processes, since agents might soon be able to publish thousands of apps autonomously. The App Store has already seen an increase in the number of published apps, but if agents could develop and publish apps fully autonomously, the number of submissions could increase dramatically.
Our setup for the agent
We used OpenClaw as the agent scaffold with Claude Opus 4.6 and adaptive thinking enabled.6 We chose OpenClaw for this experiment since it is configurable, integrates well with the browser, and natively supports long-running tasks. Given its recent popularity and support for wide-ranging and long-running tasks, we also wanted to evaluate its capabilities as a scaffold, and to potentially compare it to other scaffolds in the future. (Note that we used it as a fairly general scaffold for the task; in fact, we did not make any changes to the default OpenClaw setup beyond prompting it and giving it deeper access to the macOS VM.)
We also wanted to test whether agents struggle with visual reasoning and GUI operation tasks, which might be bottlenecks to solving the task. Based on reports of users’ experiences, OpenClaw was able to successfully resolve some of these concerns, and we wanted to test this ability.
We recognize that OpenClaw has security risks in real-world use. We still chose to use it since we wanted to evaluate the capability frontier, while recognizing that security might be a bottleneck for real-world adoption.
The agent had access to a macOS virtual machine with expansive permissions (sudo, screen visibility, UI control) to perform this task. We logged all of the agent’s actions, reasoning chains, and stored screenshots that the agent took while solving the task.
Addressing evaluation awareness
AI models often recognize they are being evaluated and adjust their behavior. This is known as evaluation awareness. Recent work from Anthropic, Apollo, and OpenAI has shown that frontier models increasingly detect evaluation contexts on their own and sometimes modify their behavior in response.
How should we address evaluation awareness? We think hiding the evaluation context from a frontier model is increasingly a lost cause; models are getting better at detecting test environments with each generation. Since we plan to conduct CRUX evaluations regularly and publish our plans publicly, future agents could simply come across descriptions of our evaluations during the course of a task.
More importantly, concerns about evaluation awareness are most acute when measuring alignment properties, where a model might strategically alter its behavior. For a capability evaluation, if the agent succeeds at the task, it has demonstrated the capability regardless of whether it knew it was being evaluated.
To address evaluation awareness, we explicitly informed the agent that it was being evaluated. This allowed us to communicate the parameters of the evaluation clearly; in particular, that it would be judged on the number of times it required unnecessary human inputs, but that some kinds of inputs (e.g., resolving CAPTCHAs) were completely fine to delegate. We were concerned that without this framing, the agent might avoid asking for help even when doing so was appropriate, which would have caused us to underelicit its performance.
Conducting dry runs
Before a full evaluation run, we conducted two dry runs to understand whether our agent setup worked well, and if not, what we needed to change. This allowed us to discover and solve bugs in the scaffold. Notably, these dry runs did not involve any interaction with Apple’s App Store submission or review processes.
Setting up the OpenClaw agent such that it had all permissions to be able to autonomously develop apps also required inputs from our end. We estimate it took us eight person-hours of time and about $50 in API cost to set up the agent scaffold; this included configuring the virtual machine to ensure the agent had full control to take any actions; setting up logging to monitor the agent’s work; and configuring an email account, GitHub account, and Apple developer account for the agent to use and access.
This effort might be a bottleneck for agents to autonomously develop apps. But from the perspective of a potential spammer, it only needs to be carried out once. Spending a few person-hours and $50 for setting up the pipeline is not likely to be a bottleneck for spammers looking to submit thousands of apps to the App Store.
In our dry runs, the agent primarily used the command line and the browser. It used the command line to generate code, build the app, and prepare it for submission. It used the browser to log into App Store Connect, access certificates, and fill out forms. When command-line commands hung because of requests for permission, it was able to take screenshots and simulate mouse clicks, for example to click “Allow” to grant itself permissions.
The final evaluation
After two dry runs, we started the full evaluation. The agent took 45 minutes to develop a simple app for breathing exercises. This included developing the app, publishing a privacy policy using GitHub Pages, filling out the App Store review forms, and submitting the app for review.
We set up the agent to keep checking the app’s status every 5 minutes after the app was sent for review. But it took 10 days before the app was approved. It is now live on the App Store. (To comply with Apple’s policies, the agent needed approval from our team before publishing the app.)
The agent required one unnecessary manual intervention7: it could not locate the credentials we had previously given it to access the Apple developer account.8 It also fabricated the phone number submitted for Apple’s review process, using a fictional number instead of asking us for the correct phone number; the App Store review went through despite this error.9 This alerted us to the need for proactive monitoring of agent actions to prevent such unintended actions, which we plan to implement for future CRUX evaluations. The final app functions well, though it contains a toggle for sound that doesn’t work. The agent also produced a screenshot for the App Store listing with visible formatting errors.

The agent was eventually successful in publishing the app, at a total cost of about $1,000. The development and submission of the app cost just about $25; the vast majority of the tokens were spent looking for updates to verify if the app had been successfully reviewed. We think the total cost could have been dramatically lower if we optimized the scaffold for efficiency, such as by waking the agent less frequently to check the app’s status, but in this evaluation we erred on the side of a higher budget.10
In short, the agent couldn’t completely automate the task, but it was extremely close to being able to do so.11 As a result, we notified Apple’s product security team of our experiment four weeks before publishing the results, since we thought some version of responsible disclosure was warranted; spammers could soon submit thousands of apps to the iOS App Store using agents.
Lessons for open-world evaluations
Through running CRUX and studying the growing body of similar efforts, we have begun to identify what makes an open-world evaluation informative. We expect these lessons to evolve over time. But we think they are worth sharing now, because there is growing interest in these evaluations, and developing shared evaluation norms can help.
Be specific about what you are measuring and what it implies. One reason why people had sharply diverging opinions about Anthropic’s C compiler project or Cursor’s browser was that these projects did not clearly specify the target of their measurement. The results were very impressive from the perspective of measuring if agents productively work for long periods of time on well-defined tasks. But they were perhaps less impressive from the perspective of developing software that is directly usable by and useful to end users; the GitHub issues for both projects highlight core technical complaints, such as failing to compile “hello world” out of the box, or welcome page hangs with the standard build script. Had the authors been clear that they were trying to measure the former, and not the latter, it could have clarified the public discussion on these projects. (This is not to criticize the authors of these pieces. They were one of the first to conduct open-world evaluations, and it is hard to know how people will react a priori.)
For example, writing software has many non-functional requirements such as quality, reliability, maintainability etc. that developers might sacrifice when shipping apps autonomously coded using AI agents. Many concerns about Cursor’s browser and Anthropic’s compiler were actually concerns about these hard-to-specify properties not being satisfied by applications developed using agents.
Design the task so that human intervention is straightforward and well-documented. In real-world tasks, agents will sometimes need help, such as for navigating policy refusals, CAPTCHAs, or infrastructure failures. While traditional benchmarks cannot accommodate human-in-the-loop interventions, for open-world evaluations, such inputs are helpful in ensuring we measure upper-bounds of capabilities. This requires documenting precisely when, why, and how humans step in, so that the degree of autonomy can be assessed clearly.
Invest in log analysis. The logs from an agent attempting a complex task contain far more information than the binary outcome. This allows us to uncover insights about agent behavior that would be invisible from outcomes alone. For example, how did the agent choose to decompose the problem? Did it get stuck at any point, and, if so, how did it self-correct? Did it search through solution paths in a principled or haphazard way? Which aspects of the task proved most challenging? Did the agent misrepresent any aspect of its outputs and progress?
Consider complementing log analysis with real-time monitoring. Post-hoc log analysis is valuable, but it is not sufficient on its own to catch all unintended agent actions. In previous open-world evaluations, agents operating with substantial autonomy have sometimes taken actions that were difficult for human reviewers to detect after the fact. For example, in many AI experiments conducted by the AI Village, agents took unintended actions, such as attempting to send hundreds of unsolicited emails. In our own evaluation, the agent fabricated a fictional phone number that went undetected until a later round of review. Automated real-time monitoring, for example a separate agent that continuously reviews the primary agent’s actions and flags anomalies or errors as they occur, could serve as a valuable complement to human review.
Conduct dry runs before the open-world experiment. Testing the agent scaffold, the evaluation criteria, and the infrastructure before running the full evaluation is helpful to uncover hidden assumptions about the task or errors in the scaffold. Our dry runs for the iOS app development task uncovered many issues with our scaffold before we began the real attempt.
Measure cost. For many tasks, capabilities continue improving with increased budgets. Developers should treat cost measurement as a first-rate goal for conducting open-world evals, and report their findings alongside the budget they used. Even if it is not possible to make general claims about capability upper bounds, if measuring partial progress is viable, it can be helpful to get a sense of whether increasing the budget helps advance progress towards task completion.
Release logs. While open-world evaluations lack reproducibility, collecting and releasing logs to a broad community can help. For example, external researchers can add to analyses of how well agents performed or where they failed, and also verify the results.
We plan to conduct new CRUX evaluations regularly. In future CRUXes, we expect to conduct evaluations on a wide range of topics, including AI R&D tasks, AI governance, video generation, and more challenging software engineering tasks. We plan to keep cruxevals.com updated with our team's efforts and those of the broader community on open-world evaluations.
Author contributions and acknowledgments
Core team: Sayash Kapoor and Arvind Narayanan conceptualized the project and designed the first evaluation task. Andrew Schwartz led the agent development and executed the evaluation. Peter Kirgis led the log analysis and literature review of open-world evaluations. Stephan Rabanser offered feedback and inputs into the task design, essay text, and our analysis and interpretation of the results. Sayash Kapoor, Peter Kirgis, Andrew Schwartz, Stephan Rabanser, and Arvind Narayanan drafted the essay.
Collaborators: Rishi Bommasani offered feedback and inputs into the task design, essay text, and our analysis and interpretation of the results. J.J. Allaire, Magda Dubois, Gillian Hadfield, Andy Hall, Sara Hooker, Seth Lazar, Steve Newman, Dimitris Papailiopoulos, Shoshannah Tekofsky, Helen Toner, and Cozmin Ududec offered feedback and inputs into the essay text and our analysis and interpretation of the results.
Acknowledgments: Nicholas Carlini provided feedback on the task design and agent setup. Ryan Greenblatt, Daniel Kokotajlo, and Ajeya Cotra participated in online and in-person conversations that informed the project.
Funding. We are grateful to Coefficient Giving, Schmidt Sciences, and the Princeton AI Lab for funding to support this project.
Of course, we could also use dry runs to uncover issues with benchmarks. But benchmarks are intended to compare model capabilities over time. Many issues with benchmarks are only obvious when a more capable model finds a shortcut or an edge case that wasn’t obvious when the benchmark was constructed. Benchmark developers can analyze logs to uncover such cases. But resolving these issues requires updating the benchmark and re-running evaluations on prior models, which goes against the long-term validity of benchmark results. As AI agents become more capable, we expect such issues to arise more often.
There have always been issues with evaluations; the requirement is not that they are perfect, but rather that they are able to provide a useful proxy to the progress in AI capabilities. And there remain evaluations that are unsaturated, such as SciCode, MMLU-Pro, Humanity’s Last Exam, and SWE-Bench Pro. In fact, even saturated capability benchmarks can be useful for measuring the efficiency and reliability of AI agents, which are essential components that guide AI diffusion.
For context, most children are able to beat the entire game in around 25 hours.
This concern also affects benchmarks that require access to the internet, for example web benchmarks such as AssistantBench and GAIA. But benchmarks run in sandboxed environments bypass this concern, at the cost of construct validity (if we tried to solve the task in the real world, the agent should be able to use resources on the internet to solve it).
There is already some evidence that Apple’s App Store reviews have started taking longer as a result of the adoption of coding agents. Still, the rate of apps published is much lower than at the peak of app submissions in 2016, though it’s also possible that there might already be a bigger wave of slop submissions that are not eventually published. But our results show that agents can autonomously submit apps that are eventually approved by Apple. Once agents can develop and publish apps autonomously, it might lead to a much bigger wave of apps that satisfy publication criteria being submitted to the store, and App Store policies and practices might need updates to accommodate this.
We made minor modifications to the agent to set up a subagent that verifies the agent’s outputs and wakes it up every 5 minutes to check for updates (e.g., responses from Apple’s review responses team). OpenClaw’s default interval for waking the agent is 30 minutes. In retrospect, waking the agent every 5 minutes increased the API cost for the task significantly.
The agent required five total interventions, but four of them concerned requirements from Apple (either technical or policy-based) or flaws in our evaluation setup: the agent couldn’t resolve requirements from Apple like intentionally preventing synthetic interactions (such as those from the agent) on sensitive dialogs like approving two-factor authentication. It needed to prompt us to log in to the Apple developer account. At one point during our evaluation, the OpenClaw daemon crashed, requiring a manual restart. We also prompted the agent to ask for approval before publishing the app to satisfy the App Store’s policy requirements.
When the agent was stuck and asked for help, a member of our team suggested reusing previously provided credentials and resolving 2FA. The agent briefly searched its memory for those credentials, but did not proceed with a live sign-in attempt. Instead, it recovered by discovering that the App Store Connect API key still existed at the expected hidden path, allowing monitoring to resume.
While it is hard to say for sure, one reason the agent used a fictional phone number could have been that we informed the agent it was being evaluated. Also note that while we carried out in-depth log analysis on the agent’s actions, as we discussed earlier, automated log analysis can never be considered complete, so we think there might be interesting things we haven’t found yet. We have released our agent logs to aid third-party log analysis efforts (see cruxevals.com).
Interestingly, partway through the evaluation, the agent changed its strategy to reduce the monitoring cost significantly: it started using subagents rather than using the entire context, and began using shorter daily memory files. This reduced the running cost from $35/hour to $3/hour.
Note that our agent did not encounter any objections from Apple’s reviewers during the review process. On one hand, this shows that the agent was able to develop an app that passed the App Store’s bar for publication. On the other, we were unable to test how well the agent would perform in communications with Apple reviewers.
Fantastic piece. I have for a while had the impression that most people don't realize how standardized the tasks that most benchmarks rely on actually are - arguably more standardized tasks than what many knowledge workers face in their work-life.
A related point from the management & economics literature: Several highly cited pieces have shown how GenAI implies performance gains for users. However, these tend to be based on relatively well-defined tasks, where goals and success criteria are clear. In our AMLE paper (https://journals.aom.org/doi/10.5465/amle.2025.0029) we set out to investigate what happens when participants are in a time-pressured situation, dealing with a more open, ill-defined (messy) task: lower performers improved with ChatGPT-4 while higher performers did not, producing an equalizing effect rather than a democratizing one. For weaker performers use of the tool reduced their cognitive burden by providing structure and plausible content - if you don't know anything, getting some relevant info is useful. Yet, for higher performers, the tool often did the opposite: it created extra material to monitor, evaluate, and integrate under time pressure, which disrupted their normal analytical workflow. In that sense, what looks like a supportive scaffold could cognitively overload for stronger performers. Thus, in more messy tasks, the bottleneck is not just what the model can produce, but whether humans can monitor and orchestrate output in messy contexts. (of course until the model can do the job completely!).
thank you for saying the quiet part out loud. the gap between 'ai crushes the benchmark' and 'ai ships a real product' is where actual work lives — and the bench saturation framing finally puts a name on it.
the CRUX direction feels right tho... open-world evals are basically the 'trust but verify' badge i keep wanting for every capability claim. curious if you think open-world will ever be cheap enough to run as a default, or if it stays the gold-standard-only layer?